Публикации
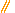 FreePascal
FreePascal
Тест производительности кода Java и FPC на Anrdoid'е |
10.03.2014 Александр Савиных |
Я провёл несколько тестов с целью сравнить производительность кода на Java и FPC на операционной системе Android.
В этом документе я описываю какие результаты мне удалось получить и также некоторые подробности о том, как именно тестировал производительность и как получил эти результаты.
Предыдущие исследования
Вот что мне удалось найти: http://blog.naver.com/simonsayz/120196955980.
Некий Yi Xian проверяет производительность... пустого цикла. Ну почти.
Вот часть скриншота из той записи:
Здесь у автора получилось, что код на FreePascal выполняет этот цикл за 3 секунды, а код на Java выполняет его за 3.4 секунды. Я посчитал такой тест слишком поверхностным, и поэтому решил протестировать производительность более масштабно.
Подготовка тестовых данных
Я решил тестировать перемножение матриц. Можно было бы генерировать матрицы случайным образом и в коде на Java, и в коде для FPC, однако я решил сделать так, чтобы использовались заранее подготовленные данные. Таким образом я исключил влияние рандома на результаты тестов. Чтобы генерировать тестовые данные, я создал небольшое приложение для Windows; файл проекта: AnWoSp\PJBench\pas\PJMatrixGenPro.lpi (в конце статьи будет ссылка на архив с проектом).
Вот какого вида XML-файл создаёт вспомогательное приложение:
<?xml version="1.0" encoding="utf-8"?>
<matrixList>
<matrix width="3" height="3">
<column>
<cell>-17</cell>
<cell>59</cell>
<cell>-98</cell>
</column>
<column>
<cell>-47</cell>
<cell>-90</cell>
... ... ...
Корневой элемент 'matrixList' (список матриц), в нём элементы 'matrix' (матрица), в них в свою очередь элементы 'column' (колонка) и 'cell' (ячейка). В финальном варианте теста было 100 матриц размером 10x10. Каждая ячейка матрицы содержит целое число от -100000 до +100000. Этот файл я назвал data.xml. После того как файл сгенерирован с помощью программы PJMatrixGenPro, его нужно положить в подпапку assets папки с Android-проектом Eclipse ADT.
Тестовое приложение
Для тестового приложения, которое должно было работать на Андроиде я не использовал Android Module Wizard, а так же я не использовал LCL. Для работы мне понадобилось вот что:
- Lazarus (использовал версию 1.2 RC 2)
- Кросскомпилятор FPC 2.7.1 с 64-разрядной Windows на Android ARM
- Eclipse ADT
- Android NDK r9c
- Android NDK - привязки для FPC, немного отредактированные мною
- Модуль EpikTimer, который я скопировал из библиотеки fptest
- Телефон с Андроидом, который я использовал для запуска тестового приложения: DNS S4001 с системой Android 4.0.3, процессор одноядерный с частотой 1Ghz
Здесь я не описываю подробно как скомпилировать кросскомпилятор и настроить его чтобы компилировать нативные библиотеки для Android-ARM, так как статьи на эту тему уже есть. Для начала можно посмотреть здесь: http://wiki.lazarus.freepascal.org/Android
Я организовал взаимодействие между кодом на Java и кодом на FPC с помощью Java Native Interface. Файл проекта размещён в подпапке pas проекта Eclipse: AnWoSp\PJBench\pas\PJBenchPro.lpi. Проект Eclipse это папка AnWoSp\PJBench, а папка AnWoSp это моё рабочее пространство Eclipse. (Существует такое понятие "рабочее пространство" в Eclipse, обозначает папку с проектами).
Вот какой код можно увидеть в главном файле тестового приложения PJBenchPro.lpr:
procedure SetPackagePath(aEnv: PJNIEnv; aThis: jobject; aJavaString: jstring); cdecl;
...
procedure Test(aEnv: PJNIEnv; aThis: jobject); cdecl;
...
begin
RegisterProc('SetPackagePath', '(Ljava/lang/String;)V', @SetPackagePath);
RegisterProc('Test', '()V', @Test);
Это позволяет вызывать методы динамической библиотеки из Java; вот как они объявляются в Java:
public class MainActivity extends Activity {
protected native void SetPackagePath(String filePath);
protected native void Test();
Таким образом из Java можно вызывать эти методы.
Сборка и запуск проекта осуществляется следующим образом:
- Если нужно, меняем код проекта PJBenchPro, затем компилируем его. При этом файл libPJBench.so кладётся в подпапку Eclipse-проекта libs\armeabi
- Далее вносим нужные изменения в код проекта Eclipse
- Если файл libPJBench.so изменился (а это происхоидт если внесли изменения в Pascal-часть), то нужно в Eclipse в Package Explorer'е выделить проект PJBench и нажать F5 либо Refresh в контекстном меню, иначе Eclipse может "не заметить", что один из файлов проекта изменился и посчитать, что пересборка проекта не требуется
- Подключить телефон если он ещё не подключен. Должен быть установлен драйвер ADB для используемого телефона
- В Eclipse вызываем контекстное меню для PJBench, Run As -> Android Application, далее выбираем наш телефон. Можно поставить галочку "всегда запускать на этом телефоне", тогда выбирать телефон каждый раз не придётся. Так же при всех последующих запусках можно пользоваться кнопкой Run в верхней панели кнопочек в Eclipse, при этом среда будет автоматически собирать установочный файл приложения и устанавливать его на телефон, а сразу после установки запускать
- Чтобы создать установочный .apk-файл, в контекстном меню проекта в Package Explorer в Eclipse можно нажать Android Tools -> Export unsigned application package...
Про этот метод сборки приложений на Android и про то как использовать JNI для организации взаимодействия кода на Java и FPC я узнал изучая код библиотеки ZenGL. Там же есть пример вызова методов Java из FPC (для тестового проекта мне это не понадобилось, в нём я только вызываю FPC-процедуры из Java).
Загрузка данных
Вот как у меня загружается XML-документ с тестовыми данными в java:
protected Document loadTestDocument() throws Exception {
long time = getNanoTime();
AssetManager assetManager = getAssets();
InputStream input = assetManager.open("data.xml");
DocumentBuilder builder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document doc = builder.parse(input);
time = System.nanoTime() - time;
WriteLog("XML Document loaded; time spent: " + ((double)time * nsts) + " seconds");
WriteLog("Matrices in list: " + doc.getFirstChild().getChildNodes().getLength() + " items");
return doc;
}
Файл открывается вызовом assetManager.open("data.xml"). Здесь указывают имя файла, который положили ранее в папку assets.
Вот сколько времени это заняло: 0,877 секунд. Здесь и далее везде единицами измерения времени у меня будут секунды.
Вот что ещё важно отметить по поводу Java: как правило, при первом запуске теста всё происходит медленнее, чем на втором и последующем запусках. Это связано с особенностью Java-машины, которая кэширует код, ну и на следующих запусках она запускает уже кэшированный код, а не загружает его опять. Так же там есть какие-то оптимизации, а так же псевдослучайные факторы (на системе работают всякие фоновые процессы), так что результат измерения времени получается всегда разный как для кода на Java, так и для кода на FPC, хотя для Java разброс по времени значительно больше.
В Java для измерения времени я использовал функцию System.nanoTime(). nsts это множитель для первода наносекунд в секунды, который равер 10^9 = 1000000000.
public final double nanoSecondsToSeconds = (double)1 / (double)1000000000;
protected final double nsts = nanoSecondsToSeconds;
А теперь загрузку XML-документа с тестовыми данными в коде на FreePascal:
function Load: TIntegerMatrixArray;
var
stream: TStream;
t: TimerData;
doc: TXMLDocument;
begin
WriteLog('Now unpacking data...');
ClearStart(t);
stream := CreateStream(PackageFilePath, 'assets/data.xml');
Stop(t);
WriteLog('Got data: ' + IntToStr(stream.Size) + ' bytes; time spend: ' + GetElapsedStr(t));
ClearStart(t);
stream.Position := 0;
ReadXMLFile(doc, stream);
stream.Free;
WriteLog('Pharsed XML data; time spent: ' + GetElapsedStr(t));
WriteLog('Matrices in list: ' + IntToStr(doc.FirstChild.ChildNodes.Count) + ' items');
result := LoadMatrixArray(doc);
doc.Free;
end;
PackageFilePath это путь к архиву приложения, который устанавливается в системе. Этот путь код на Java передаёт в FPC-библиотеку с помощью вызова SetPackagePath (который зарегистрирован в JNI, как описано выше). У меня этот путь: /data/app/hinst.pjbench-2.apk. Этот файл является zip-архивом. Функция CreateStream извлекает файл из zip-архива в память:
uses
zipper,
...
function CreateStream(const aFilePath: string; const aSubFilePath: String): TStream;
var
h: THelper;
z: TUnZipper;
strings: TStrings;
begin
z := TUnZipper.Create;
z.FileName := aFilePath;
h := THelper.Create;
z.OnCreateStream := @h.CreateStream;
z.OnDoneStream := @h.DoneStream;
strings := TStringList.Create;
strings.Add(aSubFilePath);
z.UnZipFiles(strings);
result := h.Result;
strings.Free;
h.Free;
z.Free;
end;
После этого распакованные данные загружаются в XML-документ: ReadXMLFile(doc, stream);
Таким образом код на FreePascal делает то же самое, что и код на Java: загружает XML-документ. Для паскаля мне удалось разбить этот процесс на 2 этапа: распаковка и парсинг XML. В Java у меня это происходит в один этап потому, что AssetManager скрывает от программиста процесс распаковки данных, и мы не знаем как он там происходит. . Скорее всего, однажды распакованный ресурс кэшируется на время работы программы, так что можно сказать что коду на Java в этой задаче в некотором смысле облегчили работу, ведь код на FPC распаковывает архив каждый раз. (На самом деле я не заметил чтобы data.xml кэшировался: разница между первым и последующим запусками java-теста для этой задачи была очень маленькая).
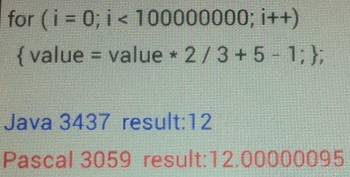
В результате выяснилось, что код на FreePascal справляется с задачей намного быстрее. На распаковку уходит 0,0181 секунд, а на разбор XML-текста 0,0483 секунд.
Итак, задача "распаковка и парсинг XML":
Java: 0.877 секунд FPC: 0.0664 секунд // 0.0664 = 0.0181 + 0.0483
Дополнение: на самом деле при желании всё таки можно было сделать, чтобы в коде на Java сначала текст XML-документа полностью загружался в память, а потом происходил парсинг, но я не стал этого делать.
Повторный запуск тестов для Java

Вот как выглядит моё тестовое приложение на экране мобильного телефона. Возможно запустить само приложение один раз и запустить тесты несколько раз. Таким образом когда я говорю, что я запускал тесты для Java несколько раз подряд, то я имею в виду, что запускал их не перезапуская всего приложения, то есть, они работали в одном и том же экземпляре Java-машины, что давало ей возможность кэшировать код. В таблицу результатов я заносил среднее значение времени по второму и последующим запускам.
Загрузка данных из XML-документа
Переходим к следующей задаче: загрузка данных из XML-документа. Когда я перемножал матрицы, я брал данные не из прямо из XML-структуры, а предварительно извлекал из XML-структуры матрицы. В Java матрицами были int[][], то есть, двумерные массивы int. Список матриц: int[][][]
Ниже представлен код загрузки матриц на Java, который использовался для тестирования:
protected int[][] loadMatrix(Node node) {
int width = Integer.parseInt(node.getAttributes().getNamedItem("width").getTextContent());
int height = Integer.parseInt(node.getAttributes().getNamedItem("width").getTextContent());
int[][] matrix = new int[width][height];
Node column = node.getFirstChild();
int x = 0;
while (column != null) {
if (column.getTextContent().trim().length() > 0) {
Node cell = column.getFirstChild();
int y = 0;
while (cell != null) {
if (cell.getTextContent().trim().length() > 0) {
matrix[x][y] = Integer.parseInt(cell.getTextContent());
y++;
}
cell = cell.getNextSibling();
}
++x;
}
column = column.getNextSibling();
}
return matrix;
}
protected int[][][] loadMatrixArray(Document doc) throws Exception {
long time = getNanoTime();
Node node = doc.getFirstChild().getFirstChild();
List matrixList = new LinkedList();
while (node != null) {
if (node.getTextContent().trim().length() > 0) {
int[][] matrix = loadMatrix(node);
matrixList.add(matrix);
}
node = node.getNextSibling();
}
int[][][] result = matrixList.toArray(new int[0][][]);
time = System.nanoTime() - time;
WriteLog("Load matrix array from xml: time spent: " + (nsts * time) + " secs");
WriteLog("Items in array: " + result.length);
return result;
}
Обратите внимание на код: if (node.getTextContent().trim().length() > 0). Он нужен потому, что Java в отличие от FPC при разборе XML-документа по умолчанию включает в структуру пробелы и переносы строк тоже. Так что, получается много "пустых" узлов. Возможно, такое поведение прописано в каком-нибудь стандарте. Могу предположить, что сохранять узлы-пробелы нужно для того, чтобы по экземпляру Document можно было полностью восстановить точную копию исходного текста, в то время как в FPC информация о том, как были расставлены пробелы и переносы строк теряется (если только не сохраняется где-то скрыто, о чём я не знаю).
А теперь код для загрузки матриц из TXMLDocument'а на FPC:
function LoadMatrixArray(const aDoc: TXMLDocument): TIntegerMatrixArray;
var
timer: TimerData;
node: TDOMNode;
width, height: Integer;
matrix: TIntegerMatrix;
x, y, i: Integer;
begin
ClearStart(timer);
SetLength(result, aDoc.FirstChild.ChildNodes.Count);
node := aDoc.FirstChild.FirstChild;
i := 0;
while node <> nil do
begin
width := StrToInt(node.Attributes.GetNamedItem('width').TextContent);
height := StrToInt(node.Attributes.GetNamedItem('height').TextContent);
SetLength(matrix, width, height);
for x := 0 to width - 1 do
for y := 0 to height - 1 do
matrix[x, y] := StrToInt(node.ChildNodes[x].ChildNodes[y].TextContent);
node := node.NextSibling;
result[i] := matrix;
Inc(i);
end;
Stop(timer);
WriteLog('Load matrix list from xml: time spent: ' + GetElapsedStr(timer));
end;
Этот код подготавливает данные в виде массива матриц: TIntegerMatrixArray = array of TIntegerMatrix; ну а сама матрица это в свою очередь двумерный массив целых чисел: TIntegerMatrix = array of array of Integer;
Я старался писать код для Java и для FPC как можно более похоже. Можно заметить как исходные коды на FPC и Java сильно напоминают друг друга и делают, в сущности, одно и то же, однако некоторых отличий мне всё же избежать не удалось.
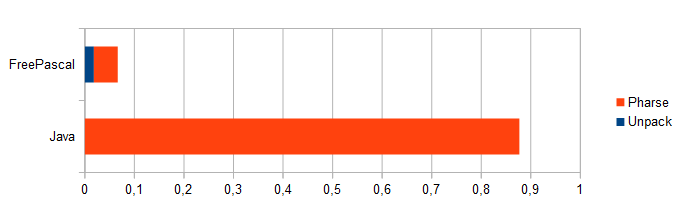
Вот результаты теста производительности для задачи загрузки матриц из XML-структуры:
Java: 0.824 сек FPC: 0.0223 сек
Код на FreePascal извлекает массив матриц из XML-структуры намного быстрее, чем код на Java.
Вычисление произведения матриц
Ну а теперь переходим к в некотором смысле основной задаче, ради которой всё и затевалось: перемножение матриц. Для этой задачи коды на Java и FreePascal получились очень похожими, практически идентичными:
Java:
// calc product of square matrices
protected int[][] prodSM(int[][] a, int[][] b) {
int w = a.length;
int[][] c = new int[w][w];
for (int x = 0; x < w; ++x) {
for (int y = 0; y < w; ++y) {
int cellValue = 0;
for (int r = 0; i < w; ++i)
cellValue = cellValue + a[r][y] * b[x][r];
c[x][y] = cellValue;
}
}
return c;
}
FreePascal:
function prodSM(const a, b: TIntegerMatrix): TIntegerMatrix;
var
x, y, w: Integer;
c: TIntegerMatrix;
cellValue, r: Integer;
begin
w := Length(a);
SetLength(c, w, w);
for x := 0 to w - 1 do
begin
for y := 0 to w - 1 do
begin
cellValue := 0;
for r := 0 to w - 1 do
cellValue := cellValue + a[r, y] * b[x, r];
c[x, y] := cellValue;
end;
end;
result := c;
end;
Эти функции вычисляют произведение двух квадратных матриц. А у меня в массиве тестовых данных 100 матриц, и вот как я решил с целью теста перемножить их между собой:
Java:
protected int[][][] bench(int[][][] matrixArray) {
long time = getNanoTime();
int n = matrixArray.length;
int[][][] resultArray = new int[n][][];
for (int i = 0; i < n; ++i)
resultArray[i] = prodSM(matrixArray[i], matrixArray[n - i - 1]);
time = getNanoTime() - time;
WriteLog("matrix products calculated; time spent: " + (nsts * time) + " secs");
return resultArray;
}
FreePascal:
function Bench(const a: TIntegerMatrixArray): TIntegerMatrixArray;
var
n, i, w: Integer;
time: TimerData;
begin
ClearStart(time);
n := Length(a);
SetLength(result, n);
for i := 0 to n - 1 do
result[i] := prodSM(a[i], a[n - i - 1]);
Stop(time);
WriteLog('matrix products calculated; time spent: ' + GetElapsedStr(time) + ' secs');
end;
Обратите внимание на код result[i] := prodSM(a[i], a[n - i - 1]); Можно это изобразить как-то так:
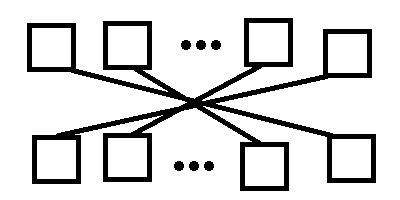
Первая матрица умножается на последнюю, вторая матрица умножается на предпоследнюю, и так далее, а в конце последняя матрица умножается на первую. Делается это совершенно одинаковым образом в коде на Java и в коде на FPC. Матрицы-результаты умножения сохраняются в отдельный массив, длина которого совпадает с количеством исходных матриц.
Результаты теста:
Java: 0.00625 секунд FPC: 0.00389 секунд
В этой конкретной задаче Java показывает самую большую разницу между первым и последующим запуском: при первом запуске код на Java затрачивает на вычисление произведения матриц 0.01 секунд, а во всех последующих запусках 0.006 секунд. Поэтому в диаграмме я разместил две полосы для Java: для первого запуска и для последующих запусков.
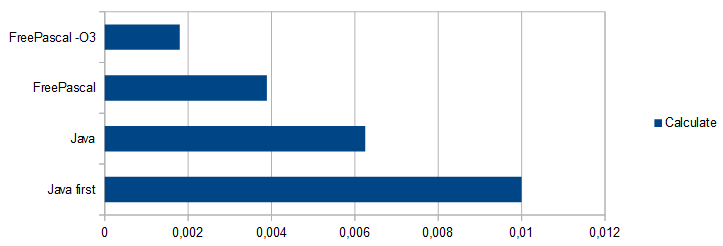
Быстрее всего работает код на FPC, ощутимо медленнее работает код на Java, и ещё медленнее работает код на Java при первом запуске. Ну и специально на случай если кому-то этот результат покажется недостаточно впечатляющим, я кроме того провёл тест с включённой оптимизацией третьего уровня -O3 в FPC (верхняя строка на диаграмме), и для данной вычислительной задачи включение оптимизации дало существенный прирост производительности. Для всех остальных задач после включения максимальной оптимизации результат почти не изменился из-за того, что большая часть вызывающегося для них кода для работы с XML и zip вызывается из RTL, так что мне пришлось бы перекомпилировать FPC RTL, чтобы получить значительный эффект. Можно было перекомпилировать RTL с оптимизацией, но я посчитал это ненужным, так как в остальных задачах FPC и так работает намного быстрее
Сохранение результатов вычислений и проверка
Первоначально этого раздела вообще не предполагалось, но я решил всё таки сделать дополнительную проверку, чтобы убедиться, что код работает правильно. Как оказалось, не зря: в коде на FPC у меня была одна незамеченная ранее дурацкая ошибка, из-за чего код на FPC перемножал матрицы размером 0 на 0. Это сильно искажало результаты тестов. Однако, благодаря проверке, которая описана в этом разделе, мне удалось исправить эту ошибку. В этой статье (всюду, в том числе и выше) приведены результаты уже с учётом всех корректировок, результаты с ошибкой я полностью заменил и перепроверил всё ещё несколько раз.
Для того, чтобы проверить правильность вычисляемых результатов, я создал код для сохранения произведений матриц в XML-файл, за одно и протестировал его производительность.
Вот код сохранения результатов на Java: (ничего необычного в нём нет: он сохраняет данные в XML-файл всё в том же формате: matrixList/matrix/column/cell, поэтому можно его просто пролистать без ущерба для понимания смысла статьи).
protected Document matrixArrayToDocument(int[][][] array) throws Exception {
long time = getNanoTime();
DocumentBuilder builder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document doc = builder.newDocument();
Node matrixListNode = doc.createElement("matrixList");
for (int i = 0; i < array.length; ++i) {
Node matrixNode = doc.createElement("matrix");
Node widthAttr = doc.createAttribute("width");
widthAttr.setTextContent("" + array[i].length);
matrixNode.getAttributes().setNamedItem(widthAttr);
Node heightAttr = doc.createAttribute("height");
heightAttr.setTextContent("" + array[i].length);
matrixNode.getAttributes().setNamedItem(heightAttr);
for (int x = 0; x < array[i].length; ++x) {
Node column = doc.createElement("column");
for (int y = 0; y < array[i].length; ++y) {
Node cell = doc.createElement("cell");
cell.setTextContent("" + array[i][x][y]);
column.appendChild(cell);
}
matrixNode.appendChild(column);
}
matrixListNode.appendChild(matrixNode);
}
doc.appendChild(matrixListNode);
time = getNanoTime() - time;
WriteLog("Save matrix array to xml document: " + (nsts * time) + " seconds");
return doc;
}
protected void saveDocumentToFile(Document doc, String filePath) throws Exception {
long time = getNanoTime();
Transformer transformer = TransformerFactory.newInstance().newTransformer();
StreamResult streamResult = new StreamResult(new StringWriter());
DOMSource domSource = new DOMSource(doc);
transformer.transform(domSource, streamResult);
String xmlString = streamResult.getWriter().toString();
BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(new File(filePath))));
bufferedWriter.write(xmlString);
bufferedWriter.flush();
bufferedWriter.close();
time = getNanoTime() - time;
WriteLog("Save xml document to file: " + (nsts * time) + " seconds");
}
protected void save(int[][][] array, String filePath) throws Exception {
Document doc = matrixArrayToDocument(array);
saveDocumentToFile(doc, filePath);
}
Процедура saveDocumentToFile получилась несколько сложнее, чем могла бы быть. Это произошло из-за того, что я хотел удостовериться, что данные полностью записываются на диск к моменту возврата из метода, иначе получилось бы "не честно". В первоначальном варианте saveDocumentToFile в качестве аргумента конструктора для StreamResult передавался экземпляр File, но в таком способе я не нашёл способа вызвать метод close или flush, поэтому получалась "отложенная" запись.
А вот код сохранения данных на FreePascal:
function CreateElement(aDocument: TXMLDocument; a: TIntegerMatrix): TDOMElement;
var
x, y, width, height: Integer;
column, cell: TDOMElement;
begin
result := aDocument.CreateElement('matrix');
width := Length(a);
if width <> 0 then
height := Length(a[0])
else
height := 0;
result.SetAttribute('height', IntToStr(height));
result.SetAttribute('width', IntToStr(width));
for x := 0 to Length(a) - 1 do
begin
column := aDocument.CreateElement('column');
for y := 0 to Length(a[x]) - 1 do
begin
cell := aDocument.CreateElement('cell');
cell.TextContent := IntToStr(a[x, y]);
column.AppendChild(cell);
end;
result.AppendChild(column);
end;
end;
function CreateDocument(const a: TIntegerMatrixArray): TXMLDocument;
var
i: Integer;
matrixList: TDOMElement;
begin
result := TXMLDocument.Create;
matrixList := result.CreateElement('matrixList');
for i := 0 to Length(a) - 1 do
begin
matrixList.AppendChild(CreateElement(result, a[i]));
end;
result.AppendChild(matrixList);
end;
procedure Save(const a: TIntegerMatrixArray; const aFilePath: string);
var
doc: TXMLDocument;
time: TimerData;
begin
ClearStart(time);
doc := CreateDocument(a);
Stop(time);
WriteLog('Save matrix array to xml document: ' + GetElapsedStr(time) + ' seconds');
ClearStart(time);
WriteXML(doc, aFilePath);
Stop(time);
WriteLog('Save xml document to file: ' + GetElapsedStr(time) + ' seconds');
doc.Free;
end;
Функция CreateElement используется и во "вспомогательном" приложении, которое подготавливает тестовые данные и работает под Windows.
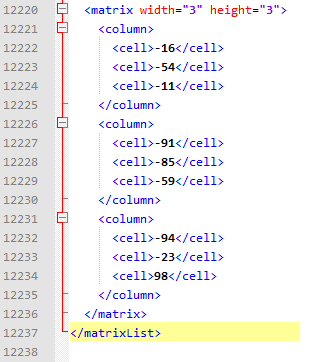
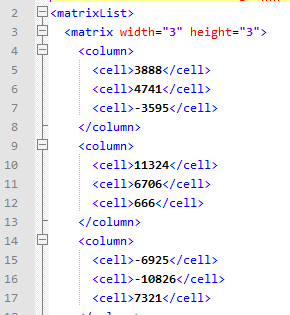
XML-файл с произведениями матриц сохранялся на SD-карту телефона в '/mnt/sdcard'. Я создаю на карте памяти два отдельных файла: с результатами работы кода на Java и с результатами работы кода на FreePascal. Вот начало содержимого результирующего файла от кода на FreePascal:
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" encoding="utf-8"?>
<matrixList>
<matrix width="3" height="3">
<column>
<cell>3888</cell>
<cell>4741</cell>
<cell>-3595</cell>
</column>
<column>
<cell>11324</cell>
<cell>6706</cell>
<cell>666</cell>
</column>
<column>
<cell>-6925</cell>
<cell>-10826</cell>
<cell>7321</cell>
</column>
</matrix>
<matrix width="10" height="10">
<column>
<cell>-666166708</cell>
<cell>-1374090177</cell>
<cell>1324272656</cell>
<cell>475097438</cell>
<cell>1168412725</cell>
<cell>-935531146</cell>
... ... ...
После того, как я исправил у себя все ошибки, содержимое файла с результатами работы кода на Java полностью совпадает с содержимым файла с результатами работы кода на FPC с одним небольшим отличием: код на Java не расставляет пробелы и переносы строк, то есть, не отформатирован, так что мне пришлось отформатировать его перед проверкой. При желании можно было бы попробовать сделать, чтобы файл был сразу отформатированным.
Можно заметить, что в самом начале матрица размером 3 на 3, а не 100 на 100, однако это не должно вводить в заблуждение. Для того, чтобы сделать ручную проверку результата перемножения матриц, я прибег к некоторому "трюку": в самом начале и в самом конце тестовых данных я поместил по одной матрице 3х3, а между ними, как и задумывалось, 100 матриц размером 10х10. Я сделал это специально чтобы можно было легче проверить правильность первого результата:
Код, использованный для создания тестовых данных:
// 3x3, 10x10, 10x10, 10x10, ... всего 100 раз ..., 10x10, 10x10, 10x10, 3x3
const
MatrixCount = 100;
procedure GenerateTestingData;
var
i: Integer;
width, height: Integer;
matrix: TIntegerMatrix;
matrixElement: TDOMElement;
matrixListElement: TDOMElement;
doc: TXMLDocument;
begin
WriteLn('Now generating testing data...');
doc := TXMLDocument.Create;
matrixListElement := doc.CreateElement('matrixList');
matrixListElement.AppendChild(CreateElement(doc, CreateRandomMatrix(3, 3, -100, 100)));
width := 10;
height := 10;
for i := 0 to MatrixCount - 1 do
begin
WriteLn('Matrix #' + IntToStr(i) + '...');
matrix := CreateRandomMatrix(width, height, -100000, 100000);
matrixElement := CreateElement(doc, matrix);
matrixListElement.AppendChild(matrixElement);
end;
matrixListElement.AppendChild(CreateElement(doc, CreateRandomMatrix(3, 3, -100, 100)));
doc.AppendChild(matrixListElement);
WriteXMLFile(doc, 'data.xml');
doc.Free;
end;
Так же можно заметить, что значения "тестовых" матриц берутся в отрезке от -100 до 100. Это тоже сделано чтобы можно было проще проверить правильность перемножения.
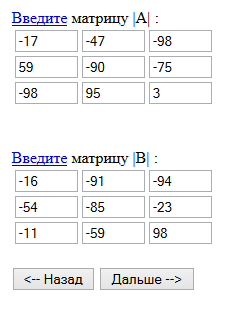
В конце я сделал проверку следующим образом: нашёл онлайн-калькулятор для умножения матриц и ввёл в него значения первой и последней матриц из файла исходных данных data.xml:
Первая и последняя матрицы, которые в соответствии с тестовым алгоритмом будут перемножены:
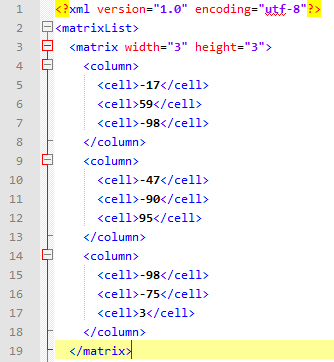 ...
... 
Сравнение результата вычислений онлайн-калькулятора и результирующего файла:
 ...
...  ...
... 
Результирующая матрица, полученная на онлайн-калькуляторе совпадает с матрицей из файла с результатами. Совпадают результаты и для FPC, и для Java, на изображении выше показан файл от кода на FPC.
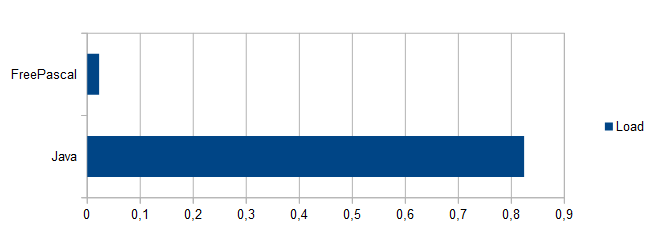
А вот сравнение производительности Java и FPC на задаче сохранения результатов в XML-файл:
- Сохранение массива матриц в XML-структуру:
Java: 0.378 сек FPC: 0.0505 сек
- Сохранение XML-структуру в файл на карте памяти:
Java: 0.518 сек FPC: 0.0307 сек
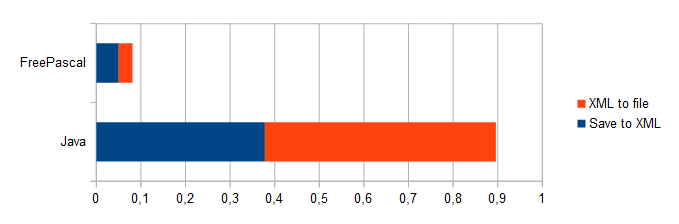
Здесь на первом этапе (синим) происходит создание XML-структуры на основе двумерных массивов целых чисел, а на втором этапе (оранжевым) полученная XML-структура записывается в XML-файл на карте памяти. Код для этих действий на Java и на FreePascal приведён выше в этом разделе.
Можно заметить, что в задаче сохранения XML-структуры в файл на карте памяти играет роль скорость записи на карту памяти, которая в некотором смысле мало зависит от того, сделан ли запрос на запись из Java-машины или из нативной библиотеки, тем не менее код на FreePascal справляется и с этой задачей намного быстрее, чем код на Java. Вероятно, причина кроется в том, что код на Java обращается к нативным Linux-библиотекам, ответственным за файловую систему, через промежуточные слои API в то время как код на FPC обращается к ним более напрямую, к тому же в последней задаче перед записью данных в файл происходит преобразование XML-структуры в текст.
Кроме файлов r.java.xml и r.fpc.txt с результатами вычислений тестовое приложение создаёт в корневом каталоге карты памяти телефона файлы fpc.log.txt и log.java.txt, в которые дублируется весь отладочный вывод для того, чтобы можно было посмотреть результаты работы приложения без подключения сборщика лога для Android. Для того, чтобы текст, записанный в log.java.txt, оказался на диске, следует завершить приложение с помощью кнопки Exit в меню приложения либо с помощью жеста перетаскивания в сторону в списке недавних приложений, появляющемся при долгом нажатии кнопки "дом".
Пример отладочного вывода от FPC-части приложения:
FPC Dynamic library initialization JNI_OnLoad Class found: True Now registering methods: 2 Register natives success: True BEF7D608 Package path = "/data/app/hinst.pjbench-1.apk" Now starting test.. Now unpacking data... Got data: 298473 bytes; time spend: 0.032164 Pharsed XML data; time spent: 0.051405 Matrices in list: 102 items Load matrix list from xml: time spent: 0.021670 matrix products calculated; time spent: 0.001733 secs Save matrix array to xml document: 0.050900 seconds Save xml document to file: 0.036277 seconds empty cycle; time spent: 0.241562 secs Now starting test.. Now unpacking data... Got data: 298473 bytes; time spend: 0.017942 Pharsed XML data; time spent: 0.048435 Matrices in list: 102 items Load matrix list from xml: time spent: 0.021526 matrix products calculated; time spent: 0.001862 secs Save matrix array to xml document: 0.050598 seconds Save xml document to file: 0.030397 seconds empty cycle; time spent: 0.200201 secs
Пример отладочного вывода от Java-части приложения:
XML Document loaded; time spent: 1.110052231 seconds Matrices in list: 205 items Load matrix array from xml: time spent: 1.3849909230000002 secs Items in array: 102 matrix products calculated; time spent: 0.012251077 secs empty cycle; time spent: 0.615418231 secs Save matrix array to xml document: 0.43670400000000004 seconds Save xml document to file: 2.808533231 seconds XML Document loaded; time spent: 0.873298385 seconds Matrices in list: 205 items Load matrix array from xml: time spent: 0.8605713850000001 secs Items in array: 102 matrix products calculated; time spent: 0.018320692 secs empty cycle; time spent: 0.616836308 secs Save matrix array to xml document: 0.44513115400000003 seconds Save xml document to file: 0.737596539 seconds
Общее сравнение по всем задачам
Вот суммарное время, потраченное на все задачи: распаковка и загрузка данных, вычисление произведений матриц и сохранение результатов в XML-файл:
Java: 2.60325 сек FPC: 0.17379 сек
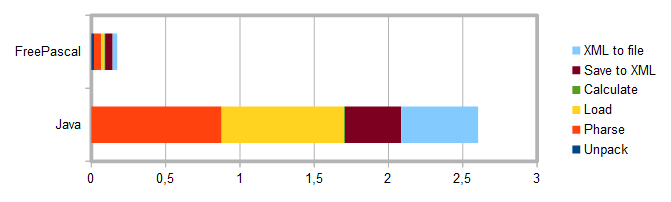
На этом графике видно, что собственно перемножение матриц заняло очень мало времени в сравнении с другими задачами: в полоске для Java зелёной части между Load и Save почти не видно, то же самое верно и для FPC. Тем не менее я считаю сравнение скорости перемножения матриц на Java и на FreePascal значимым.
Пустой цикл for
Однажды я читал в одной статье как автор выражал недовольство тем, что для тестирования производительности измеряется время выполнения пустого цикла for. Я решил провести и такой тест.
Код на Java:
protected void emptyCycleBench() {
long time = getNanoTime();
for (int i = 0; i < 100000000; i++)
;
time = getNanoTime() - time;
WriteLog("empty cycle; time spent: " + (nsts * time) + " secs");
}
Код на FreePascal:
procedure EmptyCycleBench;
var
i, j: Integer;
time: TimerData;
begin
ClearStart(time);
for i := 0 to 100000000 do
;
Stop(time);
WriteLog('empty cycle; time spent: ' + GetElapsedStr(time) + ' secs');
end;
И вот результат:
Java: 0.5 сек FPC: 0.8 сек
Не знаю почему, но выполнение пустого цикла - единственная задача, с которой код на Java справился быстрее, чем код на FPC (среди рассмотренных мною тестовых задач). Однако FPC с включённой оптимизацией третьего уровня всё-таки выполняет и эту задачу быстрее.
![]()
Проект
Я положил в архив всё необходимое для сборки моего тестового проекта:
- Рабочее пространство Eclipse ADT с проектом PJBench находится в подпапке AnWoWp
- Lazarus-проект находится в подпапке AnWoSp\PJBench\pas
- В подпапке andkb-fze находятся несколько модифицированные мною интерфейсные файлы Android NDK для FPC, оригинальные файлы находятся по этой ссылке: http://developer.android.com/tools/sdk/ndk/index.html
- В подпапке PasZUtil находятся модули, немного упрощающие работу со сжатыми данными, и которые используются в проекте
- В подпапке PasStr находятся ещё модули, которые используются в проекте
- Кроме того я положил в архив файл с скомпилированным установочным файлом приложения для Android: PJBench.apk.
Всё кроме модулей которые писал не я (EpikTimer и интерфейсы к Android NDK) я предоставляю по лицензии Modified LGPL с исключением для статической линковки (эта лицензия используется в многих библиотеках для FPC, в том числе в FPC RTL & FCL). Я заметил, что Lazarus 1.2 RC 2 работает с кодом проекта лучше всего, в то время как в Lazarus 1.0.x возникают ошибки при разборе исходного кода RTL, из-за которых не работает автодополнение.
- PJBench_Full.7z [3.8 MB]
- PJBench_Lite.zip [2.0 MB]
В Lite-версии проекта я удалил всё лишнее, что только было можно. Больше всего занимает служебная папка .metadata Eclipse, однако её удалять нельзя, иначе проект не будет строиться.
Заключение
Я думаю, что проведённые мною тесты убедительно показывают, что нативный код на FreePascal не только работает значительно быстрее, чем аналогичный код на Java, но и может быть использован для решения практических задач, для написания приложений, требующих высокой производительности
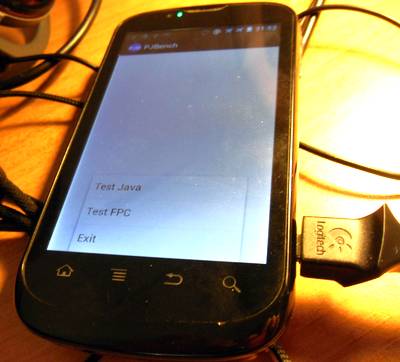
Для организации взаимодействия кода на Java и FPC мне потребовалось приложить самые минимальные усилия. В то же время можно с лёгкостью разработать пользовательский интерфейс для Android-приложения полностью на Java, как это и сделано в данном примере.
Кроме того, позволю предположить себе следующее: Java-машина по каким-то причинам "любит" простые конструкции: пустые циклы, которые она выполняет даже быстрее, чем FPC. То же самое, скорее всего, справедливо и для перемножения матриц: несколько вложенных циклов, которые обращаются к элементам массивов это достаточно простая программная конструкция, для которой Java-машина, скорее всего, каким-то образом полностью кэширует инструкции, а вот по мере возрастания количества вложенных вызовов и создания большого количества экземпляров классов производительность Java-кода падает. Что и наблюдалось в ходе теста: при перемножении матриц Java проигрывает совсем немного, а вот при работе с XML, где наверняка происходит множество вложенных вызовов, создаются экземпляры классов и выделяется память, Java проигрывает почти в 10 раз. Таким образом, если бы я решил провести какой-нибудь достаточно сложный расчёт с помощью модульной вычислительной библиотеки, то, скорее всего, обнаружил бы, что код на FPC справился бы с этой задачей с значительно более большим отрывом. Но это - в следующий раз.
Ссылки:
| FPC | 3.2.2 | release |
| Lazarus | 3.2 | release |
| MSE | 5.10.0 | release |
| fpGUI | 1.4.1 | release |